The game started with a teaser that you can view. It's only 6 minutes and it is embedded in the main page. What you learn is that in the future, 10 years from now, education is something that is tracked publicly through a block chain system like the one that powers Bitcoin. You are able to learn in many different ways and gain Edublocks from companies, universities and even other individuals. I won't spoil the video, please go watch it!
Play
To play you sign in and you play cards in the form of 140 characters of thought. There are two primary cards that you can play in the beginning - "Positive Imagination" and "Shadow Imagination". These are for playing your ideas for how you see the future playing out under these new conditions. You can play positive things you'd like to see happen in Positive Imagination and you play more negative things that you fear might happen and you wish to avoid in the Shadow Imagination.
Once you've played a few cards, you'll start to gain points. Not by playing the card, but by others building on your card. They can either like your card giving you points or they can build on your card expounding on your original idea in four different ways.
First they can "Predict" by building on your future and saying how this will evolve. You can imagine a number of prediction cards building on one another to reach farther and farther into the future. Predict cards are about the future and they allow you to be creative within the constraints of the game.
The second card is an Act card. This is a card you play that allows you to describe ideas that will either make the future more likely for positive futures or less likely in case of shadow futures. Act cards are about the now and allow you to use your existing skills and thoughts to help describe how to make these futures come to be.

The third card you can play is a Cheer card. This allows you to agree with the person. Why do you like or not like this future. This allows you to dog-pile on top of someone's existing ideas and add weight. It also lets them know they are on to something. Cheer cards are about agreement within the system.
The final card you can play is an Investigate card. This allows you to ask a question about the card someone played. You can either delve in deeper on what they are saying, choose to use a question to force them to reflect on their original ideas or just get clarification since maybe the idea was unclear. Investigate cards reflect our desire to disagree and discuss ideas that rub us the wrong way.

Once a build is started with either of the two imagination cards, they can then be built upon with any of the four remaining cards. These cards can in turn be played on one another. This means some positive or negative potential outcome is the root of every build and you have many tools with which you can respond and interact with that original idea.
Gamification
For this the gamification comes in the form of a leaderboard and scoring system. Rather than repeat the scoring system, here is the system as defined on the site when you click on your points.
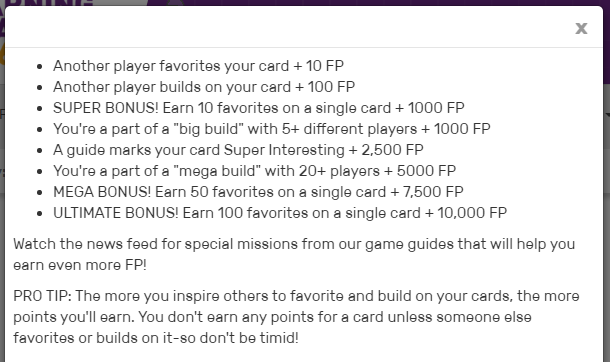
You quickly find out that you don't get points for playing cards. You get points when people favorite or like your card. Further, you learn that if another player extends your card then you get some points. Larger point values are awarded on milestones when your cards either get heavily favorited by others OR they like your idea and create really large builds. For instance, a "mega build" which includes more than 20+ players gets a cool 5000 points. Turns out this is for good reason too, since it was REALLY hard to get a mega build. There may have only been 2 or 3 the entire game.
The next thing you learn is that by getting points you level up. Certain point values will get you to the next level, where you'll receive super powers that you can use within the game, or even better, real life rewards. Some of the rewards were quite compelling to gamers like myself. For instance, at 75,000 points you got invited to future events. Of course every gamer wants to be invited to future tournaments! At 100,000 you get invited to a special discussion group on IFTF.org. There were only 4 of us in the entire event to get this award level, making it fairly prestigious.
Finally we learn that the game engineers did a good job of setting bounds. There are also awards at 250k, 500k, 750k, and 1 million. However, these were never achieved. Doing so would have required some very intense collaborative efforts by a set of gamers focused on slightly bending the rules and relying on something called boosting. We'll get more into that later ;-)
Each level came with a name. Keen, Bright, up to Legendary. These gave you some idea of how much value the designers gave to each point series. Expert was at the 250k mark and nobody reached it ;-) For me it was a goal only to achieve the 75k to get future invitations. By the end though, I had achieved nearly 120k after making some adaptations to my play style.
Meta Game
There were a couple of interesting meta games happening during the event. The first was something that I noticed which I cannot fully verify, but maybe the game creators will come along and agree. It seemed there were some players from the IFTF that maybe were playing super powers that they didn't get from leveling up. If they weren't doing this, then they could have been (and maybe should have been) to help keep the game more interesting and breath air into dead zones.
The second meta game was the Twitter angle. During the SXSWEdu keynote there was a call to arms to play the game by submitting tweets with certain hash-tags. These became cards in the system. However, they also became the largest grouping of completely unseen cards on which nobody was able to build or play. When analyzing the data set it was a stream of nearly 2000 singular cards. It is possible that they came in too fast for others to play on. Its also possible their quality was being driven without access to the cards already played in the game and thus they lacked the same level of foresight and thought as those who had spent hours on the site collaborating with others.
Whatever the reason I think that the second meta game failed. Even textual analysis of the cards showed that they were divergent and disconnected from the main game.
Gaming the Game
This was the fun part for me. At the end of the first day I was setting in 4th place and I had a pretty decent score. I knew that I wouldn't have much time to play on the second day. It was, after all, during the middle of the work week and I had a lot of great stuff to deliver.
I decided that there were two ways to increase my points. The first was to get more people to favorite my cards. This would come naturally if I had good ideas, so this wasn't worth trying to min/max within the system. The second scoring mechanism was being part of builds. This, is directly related to my own actions and not the actions of others. This was the perfect mechanic to focus on. And note, I'm saying focus on. I in no way tried to manipulate the game for points. Instead I focused on responding and replying to threads which had more relevance to me both in terms of content and potential points.
What I needed here was a way to examine the entire graph. The game itself only showed the top 20 most active futures and I was already involved in all of those. I needed the graph for thousands of ideas and builds (to view use the Open In feature, the graph is too large to be previewed by Dropbox). I started by making page requests, which contained no data. The pages were dynamic and thus the cards are populated by script after the fact. I then looked at the network traffic. They had obfuscated the traffic well enough that I didn't want to spend my time trying to reverse engineer it.
What I knew was that I was logged in and I could see all of the pages and data. I wrote a scraper that would navigate the pages and extract the content. In the process it would build the entire graph of ideas and it would alert me to graphs which I was not participating in, but that I should be participating in because the content was interesting.
Nearing the end of the event, I had scraped nearly 7000 cards and had a big enough graph that I could make my final push. Using this technique I was able to find hundreds of threads I had missed while sleeping and allow myself to come up to speed on them. I was also able to identify places where people had asked investigate cards of me that I had in turn missed. But those are questions and I wanted to try and reply to all of the questions I could.
All of this min/max work I did with only hours to go, but it taught me a lot about the game itself and potentially how to improve it.
Learning from the Game
This game taught me a ton about gamifying abstract concepts. I was truly drawn in and the idea was very intriguing. The low barrier to entry, just 140 characters, made it accessible to a large group of people. In fact by the end there were more than 2000 registered players though I don't think everyone got a chance to submit a card.
Normally games have very clear goals and scoring but this game was highly abstract and was about something that may never even happen. What value is gleaned from the cards played are really up to the players and game organizers. What can be learned from the experience has either already been learned or will be further analyzed post mortem by organization and reorganizing the cards into different structures.
Seeing this highly abstract game play out made me realize that these are the tools I needed to figure out how to change teams and organizations. Like this future concept we often work in futures when at work. We are always estimating our ability to deliver a future that may or may not happen. Having people collaborate using this structure is leaps and bounds more enabling than simpler approaches like polls, planning exercises and other games where the results are immediately available and describe concrete results.
Equally there is a lot to be learned about what the game might have gotten wrong. Let's explore that next.
Improving the Game
After developing my own tools to learn more about what was happening in the system a few inspiring ideas fell out that I think may improve the game. Some of these I found during the event and reached out to the coordinators, but I doubt there was any time available to be able to adapt the game to take them into account.
Let's start with the full graph of the system. This was my way to find interesting threads, but it could have been built into the game itself. Not being able to see all of the information that was going by meant that I was restricted to the tools given to me by the game. This was the Dashboard, which showed the most recent 30 or so cards with interesting things happening. This information was quickly consumed though and there was so much that never showed up in the Dashboard but was still very, very interesting.
I can think of several ways to build this. First, a bigger graph view that allowed exploration of more of the cards than the top 20 builds. These top 20 builds were established early on, in the first day and rarely changed.
A simple search would have been great as well. Searching for specific keywords could have enabled players who wanted to participate in certain types of conversations to focus their engagements. After all not everyone has unlimited time.
A final set of tools for finding cards of interest. For instance, showing me all cards that build on mine that I haven't yet seen or replied to. This would have hopefully made bigger more engaging builds. A random card tool could have augmented this in order to surface some of the cards that nobody had seen or replied to.
Many of these features could have even been promoted with points. Why not give an extra 5 or 10 points to being the first reply on a card that nobody has responded to yet. This would have enabled explorers within the system to seek out and engage under represented topics.
And on that topic, the handling of the Tweet cards I believe was one of the most disappointing findings of the entire event. When I discovered 2000 unseen cards with no replies, a statistical anomaly in the data set, it made me quite sad. I'm sure this was hard to foresee in the games construction, but now that we know that it exists we could avoid it. Perhaps just by focusing more on the visibility of these cards or by improving the interaction model so that anyone who tweeted was drawn into future game interactions rather than sending one-offs into the system.
My next finding is also related to improving engagement. Throughout the event ideas continuously got repeated. This is a good thing and a bad thing. First, why is it good? Well, it allows people to newly engage on prior ideas without feeling that all of the ground has been covered. This can mean that people who came in late still feel like valuable conversation is happening. Additionally you collect more data on the repeat ideas. Higher counts means more people care about that aspect of the space and you can use this to focus later games and efforts.
It can be bad because we naturally want to group and organize the graphs and prevent duplication. However, there was no way to do this within the system. No way to point users at previous posts other than to copy/paste links to the original cards. Eventually this broke down completely since nobody could find related card links to cross/post. As the game grew near the end the information got more and more unorganized and the pace picked up substantially. This actually showed up in the build graphs as deeper builds in the beginning of the event, the sea of singular tweet cards in the middle and finally very shallow and broad graphs at the end (where everyone replied many times to a top card, but never following a long train of thought).
Conclusions
I think the game was very successful overall. It definitely accomplished what it set out to do and brought awareness to an abstract concept, engaging hundreds if not thousands of people on a false future that may or may not ever come even close to true.
I look forward to participating in future games, perhaps even helping with the design and technology behind them. I definitely think I can provide more value by building and facilitating than by simply participating.
After the event I also completed my scraper so it could get more than just the card graph. I improved it to get all of the information on the card that wasn't related to scoring and made it available on Github as JSON. You can view the repository containing the raw card data.
You can also play around with the data a bit. I made a tag cloud visualization for the players. Using this you can see how the various players were focusing their efforts. For fun, I've included my tag cloud here. I spent a lot of time trying to be in character referring to "The Ledger" and "Edublocks" :-)



{kind=link}